
Everyone talks about the GPU shortage. Almost nobody talks about the memory shortage.
AI models are growing faster than memory can feed them. The gap is widening. Every generation of frontier model demands more parameters, more bandwidth, more power to shuttle data between where it's stored and where it's processed. The silicon industry is building ever-larger compute engines and starving them of the one thing they need most: fast access to memory.
The "memory wall" isn't new. Computer scientists identified it in the 1990s — a prediction that processor speeds would outpace memory speeds, creating a bottleneck that no amount of compute could overcome. For decades it remained an academic concern. Then AI turned it into an industrial crisis.
The Divergence
The chart below tells the story in two lines. The red line tracks AI model parameter growth from GPT-1 (110 million parameters, 2018) to projected next-generation models approaching 10 trillion parameters. The teal line tracks High Bandwidth Memory — the fastest memory technology available to feed these models — over the same period.
Parameters are scaling at roughly 10x every two years. Memory bandwidth is scaling at roughly 2x every two years. The lines are diverging. Each generation of model is hungrier than the last, and memory cannot keep up.
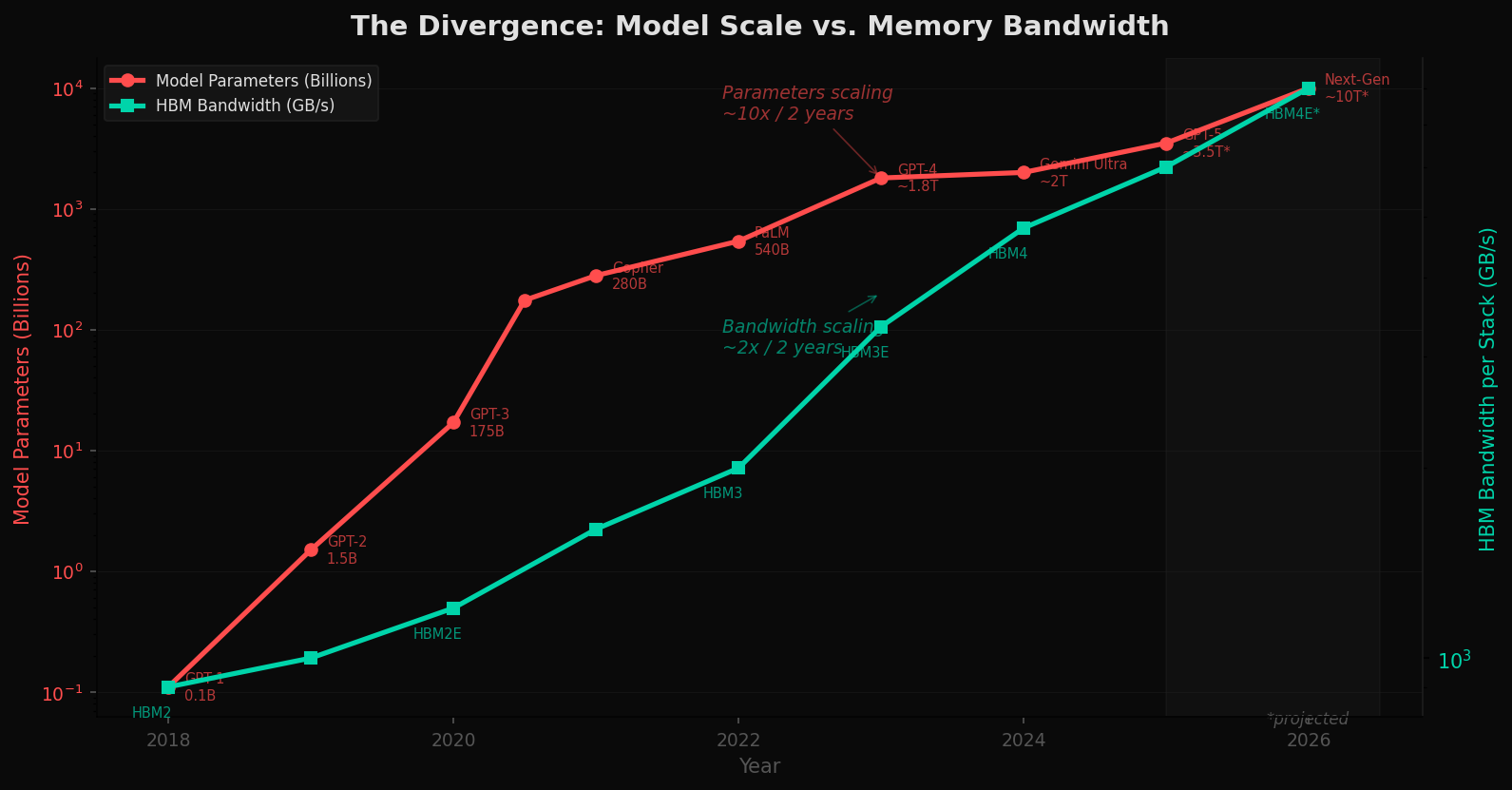
This is the von Neumann bottleneck made visible. In conventional computer architecture, compute and memory are separate, connected by a bus. Every operation requires data to shuttle back and forth. As models grow, this shuttle becomes the chokepoint — not the arithmetic unit, not the transistor count, but the pipe between memory and processor.
The Shortage
High Bandwidth Memory — HBM — is the specialized DRAM that sits on top of AI accelerators like NVIDIA's H100 and B200, AMD's MI300X, and Google's TPU. It provides the bandwidth these chips need. And there isn't enough of it.
Three companies — SK Hynix, Samsung, and Micron — control virtually all HBM production globally. NVIDIA alone consumes a massive share of total output. Demand from hyperscalers has outpaced supply since 2023, and the deficit is projected to widen through 2026.
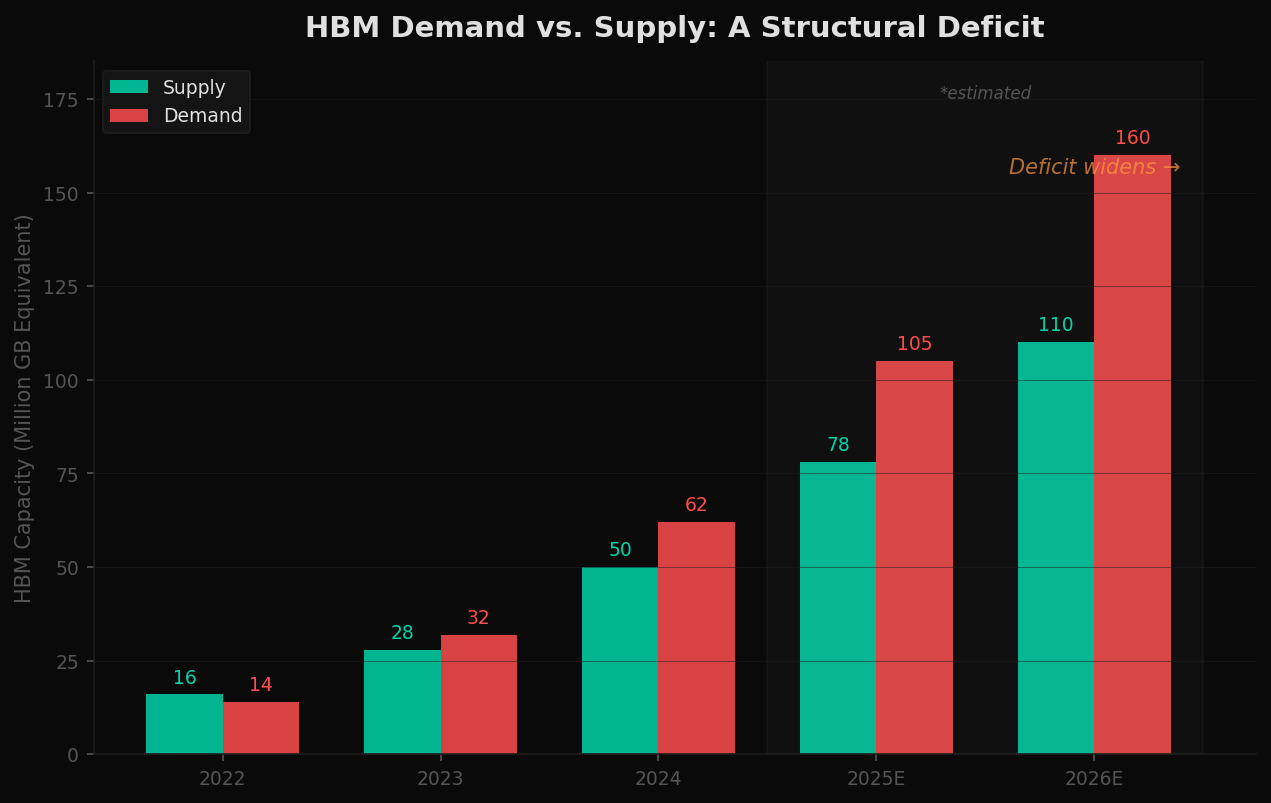
The shortage isn't temporary. Building new memory fabrication facilities takes 2-3 years and costs $15-20 billion or more. The capital cycle cannot respond fast enough to exponential demand growth.
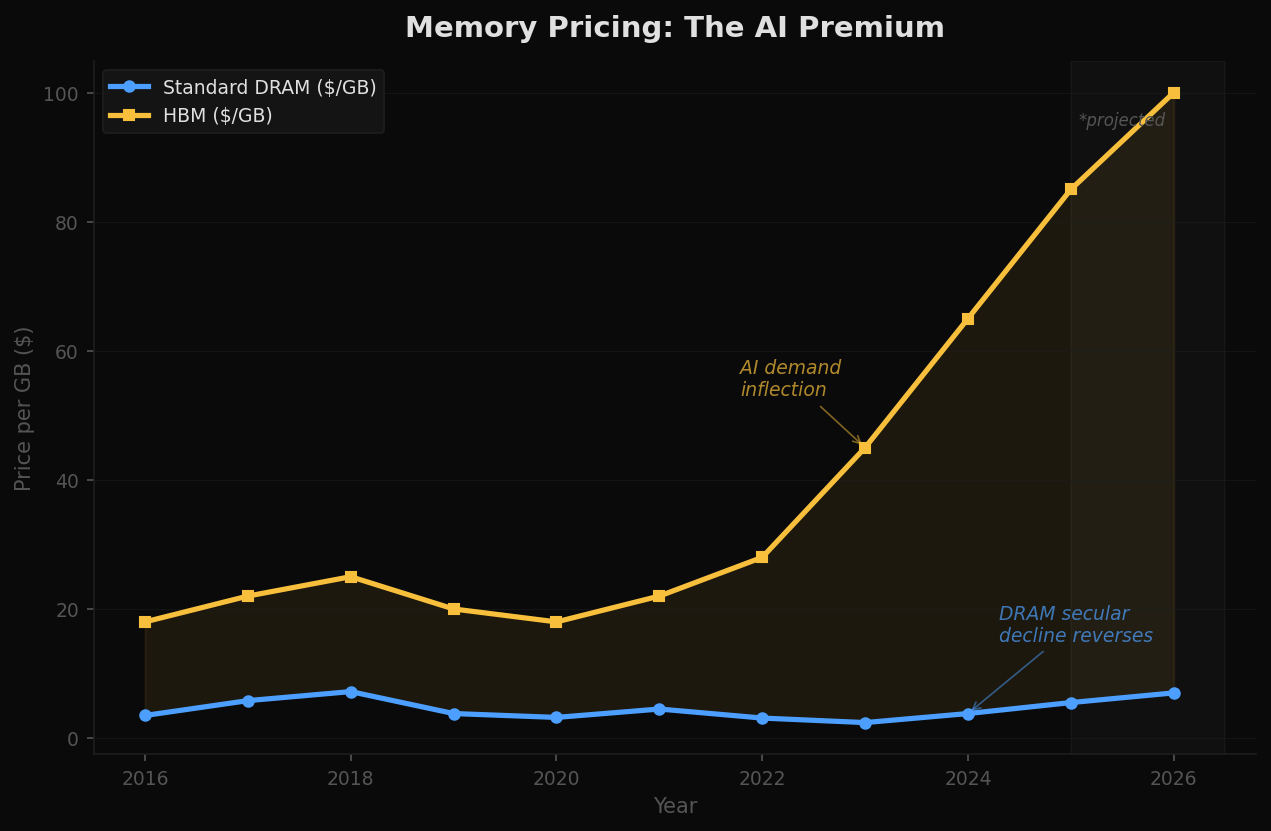
The pricing data confirms the structural shift. After years of secular decline in DRAM pricing — the long-term trend that made computing cheaper every year — AI demand has reversed the curve. HBM prices have more than doubled since 2022. Even standard DRAM has begun to climb as AI workloads consume an increasing share of global memory production.
The Power Problem
The memory wall isn't just about bandwidth. It's about energy.
A single inference on a GPT-4 scale model requires moving terabytes of parameter data from memory to compute units and back. The energy cost of this data movement — not the arithmetic, not the matrix multiplications — dominates total power consumption. And the ratio gets worse as models grow.
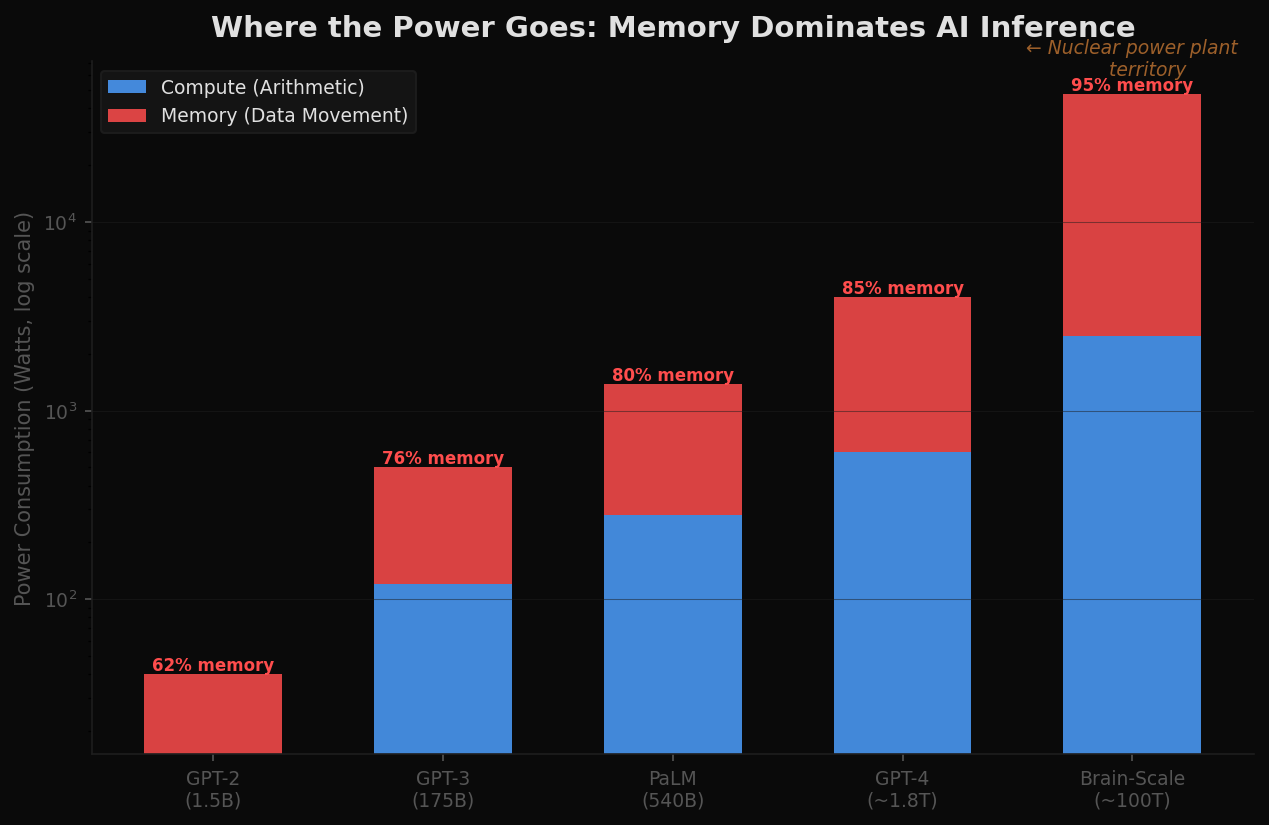
At current architecture, a GPT-4 class model consumes roughly 3-4 kilowatts during inference. Scale that to brain-level parameters — 100 trillion, roughly the number of synapses in a human brain — and the power budget under current architecture enters the tens of megawatts. That is the power consumption of a small industrial facility, for a single model instance.
Current data centers are already hitting power ceilings. Memory power consumption is a major contributor. Scaling to AGI-level systems under current architecture would require power budgets that are physically and economically impractical.
How Biology Solved It
The human brain contains approximately 86 billion neurons and 100 trillion synapses. It performs the equivalent of exaflops of computation. It runs on 20 watts — less than a laptop charger.
There is no memory bus. Synapses both store and process information simultaneously. There is no separation between "where data lives" and "where computation happens." The architecture is fundamentally different from anything in silicon: memory and compute are the same physical substrate.
The brain is also event-driven, not clock-driven. Neurons fire only when there is something to process, consuming near-zero power at idle. A conventional GPU runs its clock whether or not there's useful work to do. The brain does not.
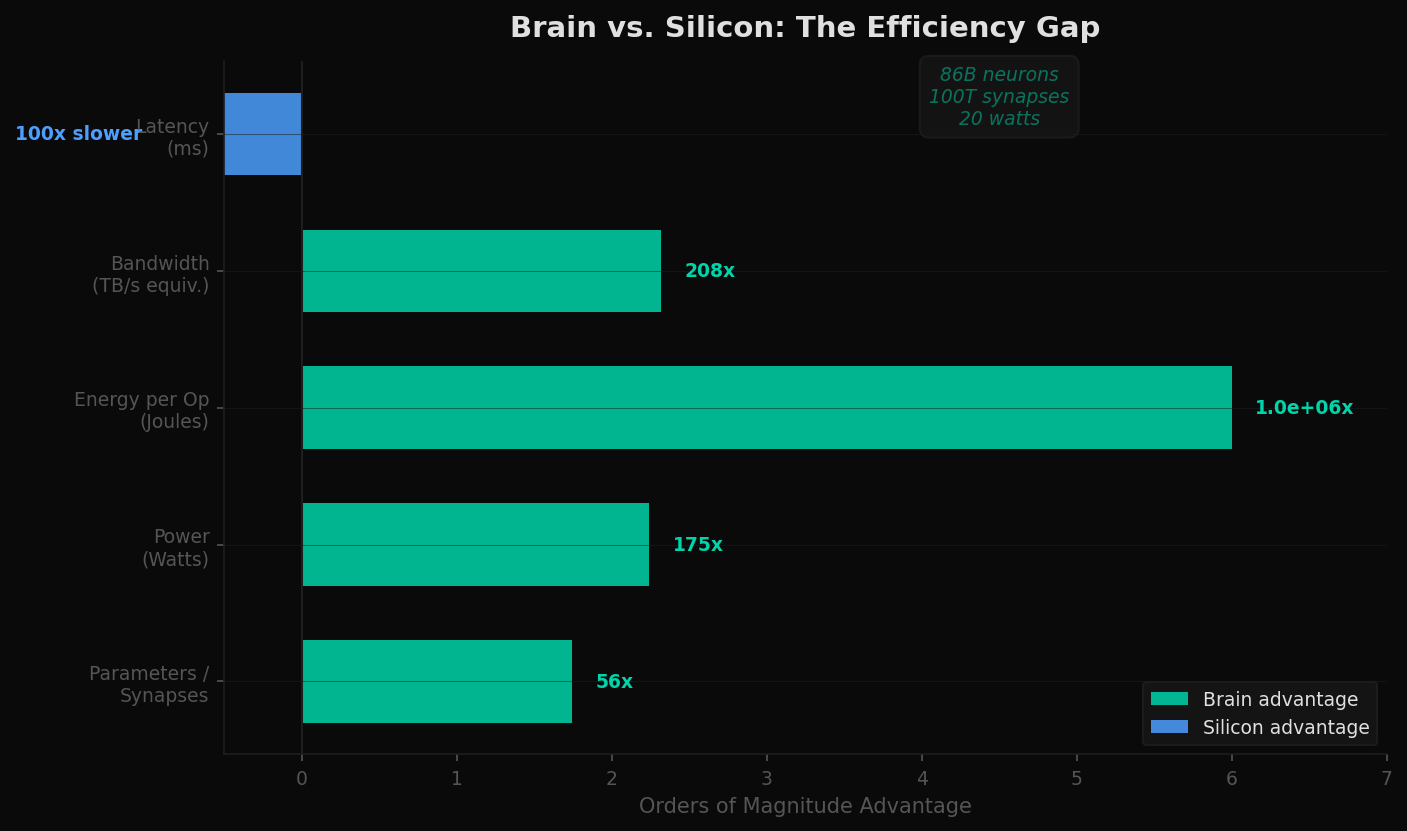
This is not aspirational hand-waving. It is a proof of existence: a physical system that achieves general intelligence at 20 watts. The architecture exists. The question is whether silicon can approximate it.
Neuromorphic Computing: The Biological Blueprint
A new class of chips attempts to replicate the brain's architecture in silicon. They are called neuromorphic processors, and they share three principles that conventional chips do not: in-memory compute (no von Neumann bottleneck), event-driven processing (no wasted cycles), and the ability to learn at the edge without cloud dependency.
The key players are early but real:
- Intel Loihi 2 — A 1-million-neuron research chip with event-driven architecture and on-chip learning capabilities. Intel's second-generation neuromorphic processor, used primarily in research settings.
- IBM NorthPole — A 256-core inference chip with 22 billion transistors that requires no external memory for inference. All parameters are stored on-chip, eliminating the memory bus entirely.
- BrainChip Akida — A commercial neuromorphic processor targeting edge AI applications. Event-driven, in-memory compute, processing sensory data (vision, audio, vibration) at ultra-low power. The most commercially deployed neuromorphic architecture.
These are not GPT replacements. They are a fundamentally different architecture suited to different problems — real-time sensor processing, anomaly detection, always-on inference at the edge. But the principles they embody — collocated memory and compute, sparse activation, event-driven processing — may be essential for AGI-scale systems.
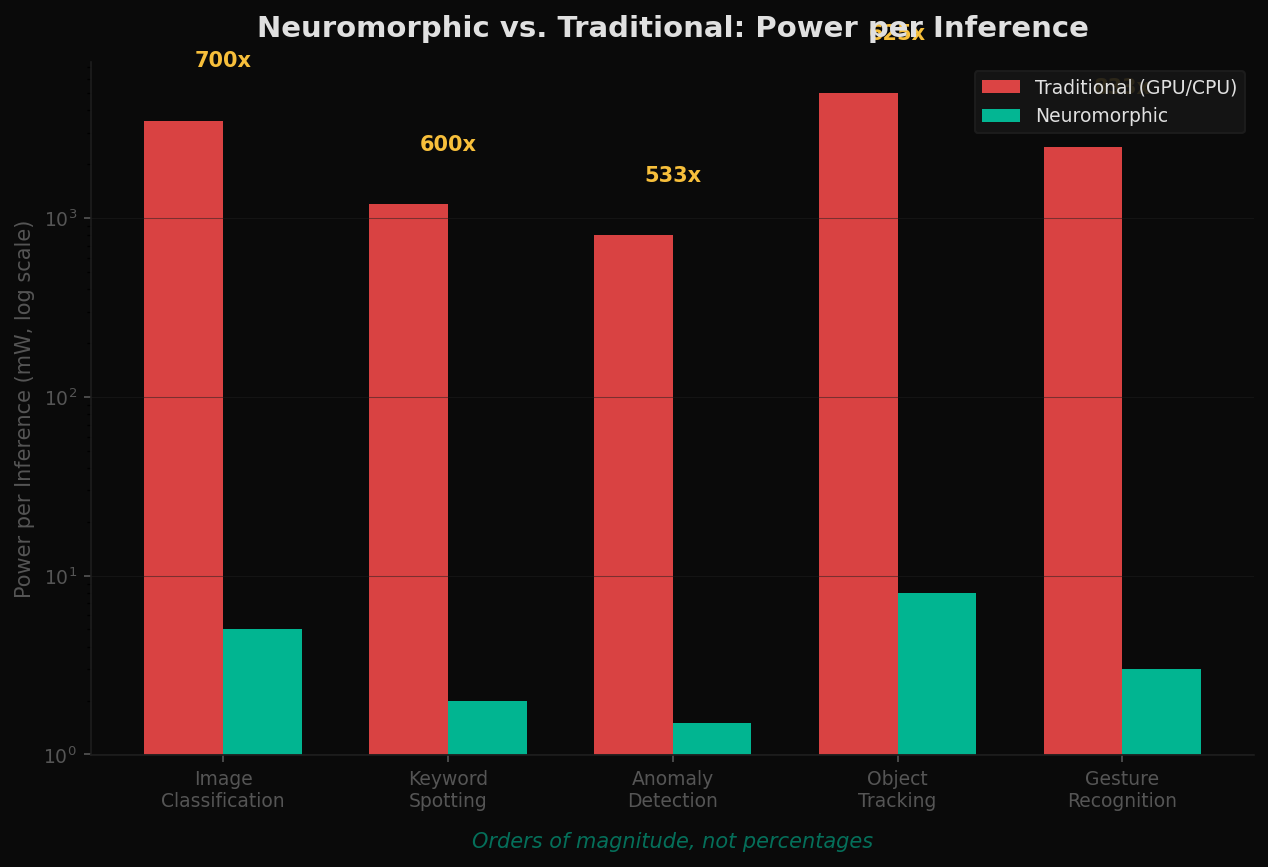
Orders of magnitude, not percentages. That is the efficiency regime that biology operates in, and that neuromorphic silicon is beginning to approach.
The AGI Constraint
What does it take to run a brain-scale model — 100 trillion parameters — under current architecture?
The numbers are sobering. Under conventional von Neumann architecture with current memory technology, the estimated power requirement for brain-scale inference is approximately 45 megawatts. That is a small power plant dedicated to a single model instance. Scale to training workloads and the number enters the hundreds of megawatts — approaching the output of a nuclear reactor.
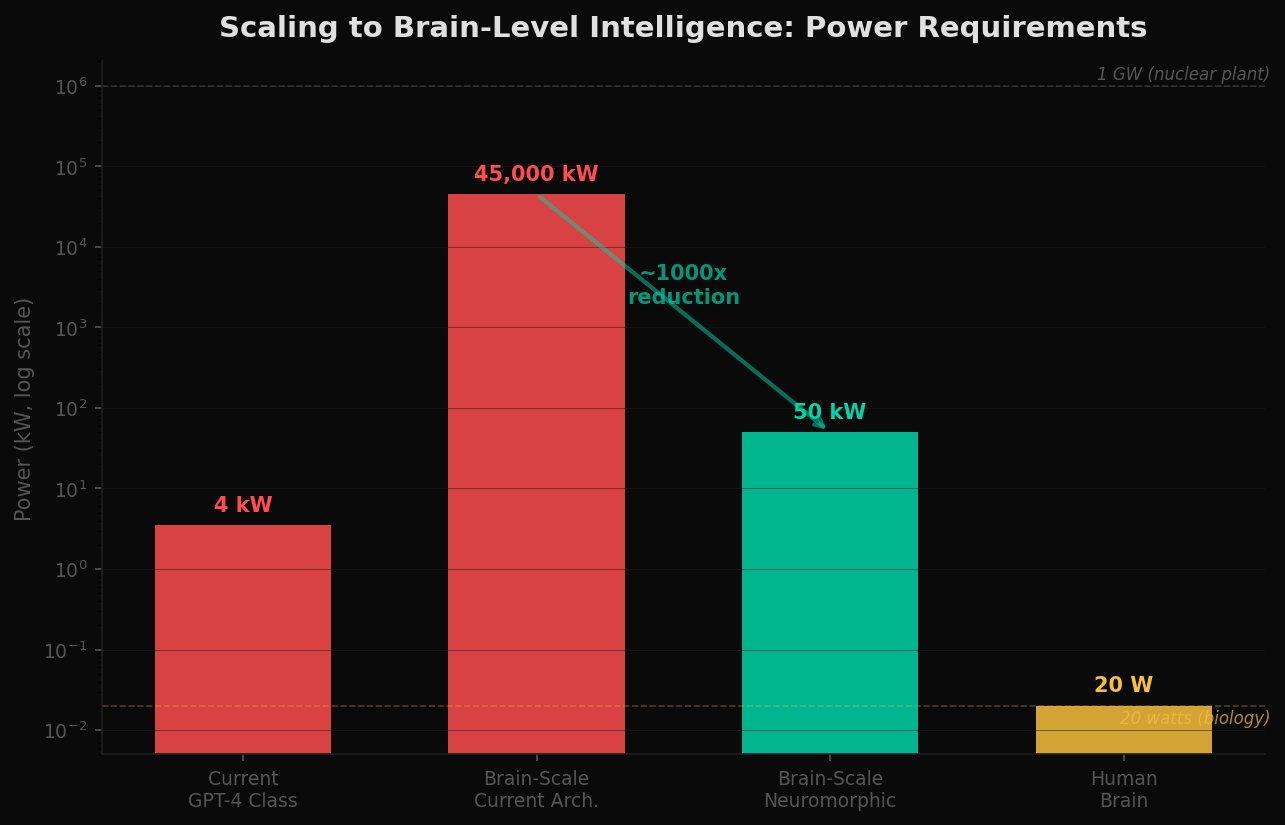
Under neuromorphic principles — in-memory compute, event-driven activation, sparse processing — theoretical power could drop by three to four orders of magnitude, approaching biological efficiency. The gap between 45 megawatts and 50 kilowatts is the difference between "physically impractical" and "deployable."
AGI under current memory architecture isn't just expensive. It may be physically impractical. A paradigm shift isn't optional — it's thermodynamically required.
The Investment Landscape
The neuromorphic computing market is early. Most companies are pre-revenue or minimal revenue. Current market size estimates range from $50-80 million in 2024. Projections vary widely, but the trajectory points toward $2-8 billion by 2030, depending on adoption curves and whether conventional scaling (HBM4, chiplets, optical interconnects) proves sufficient for the next decade.
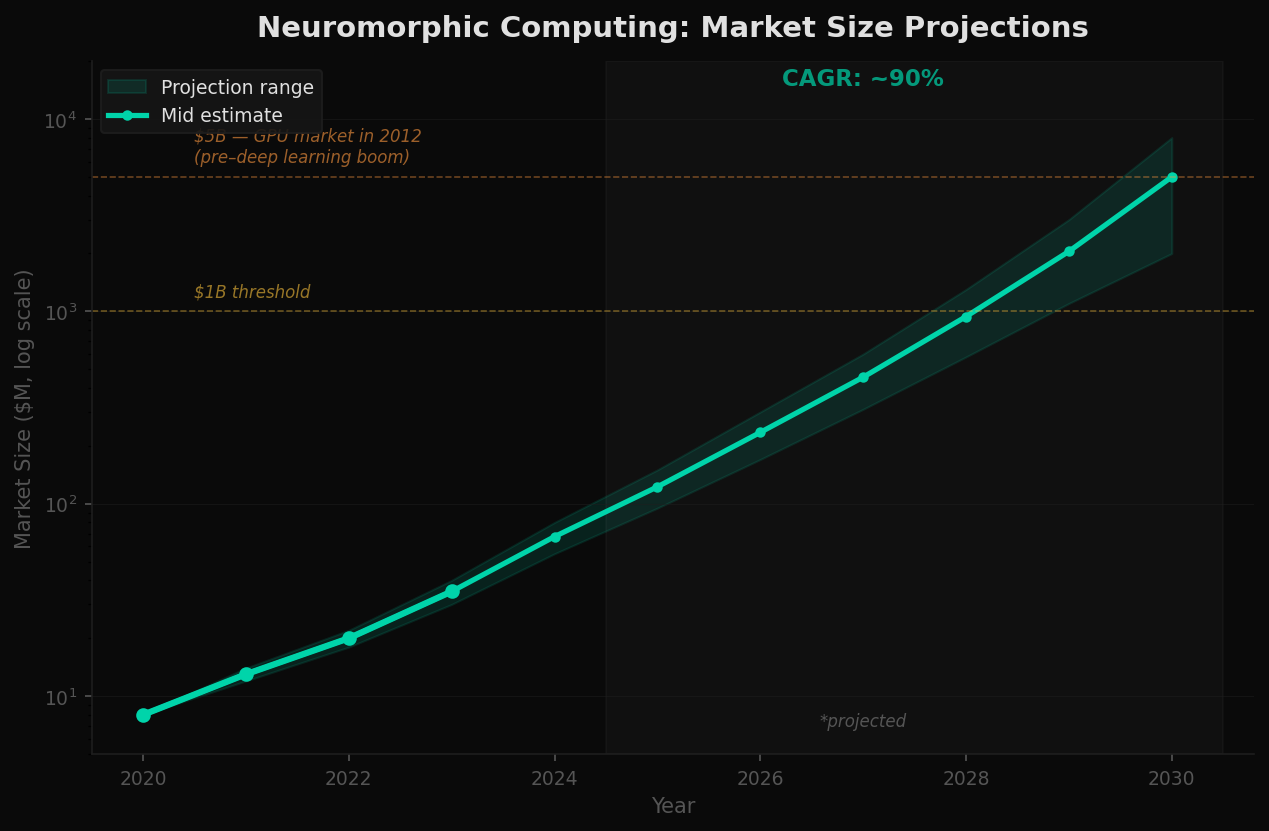
The analogy to GPUs is instructive. In 2012, the GPU market for compute was roughly $5 billion — niche, specialized, largely ignored by mainstream investors. Then deep learning created a demand shock that no one anticipated. NVIDIA's market capitalization went from $10 billion to over $3 trillion in twelve years.
Neuromorphic computing is at a similar inflection point — or it isn't. The risk is real. If conventional scaling proves sufficient for the next decade, neuromorphic may remain a niche research curiosity. But if the memory wall holds — if physics enforces the constraints the data suggests — then the paradigm shift becomes inevitable, and the companies building that different architecture become the infrastructure layer for whatever comes after transformers.
Implications
The AI industry is building ever-larger compute engines and starving them of memory bandwidth while burning unsustainable amounts of power to move data. The memory wall is not a temporary supply chain issue. It is an architectural constraint rooted in the physical separation of memory and compute — a design choice made in the 1940s that has reached its scaling limits.
Biology demonstrates that general intelligence does not require this architecture. It requires a different one. One where memory and compute are the same substrate. One where processing is event-driven, not clock-driven. One where power consumption scales with activity, not with clock cycles.
The brain doesn't have a memory bus. That's the point.
The companies and architectures exploring that different path are early, small, and largely ignored — exactly where the most asymmetric opportunities exist. Whether neuromorphic computing delivers on its theoretical promise or remains a laboratory curiosity is an open question. What is not open to question is the constraint it aims to solve: the memory wall is real, it is structural, and under current architecture, it stands between here and AGI.
Data Sources & Methodology
Model parameter counts sourced from published papers and technical reports (OpenAI, Google DeepMind, Anthropic). HBM bandwidth specifications from SK Hynix, Samsung, and Micron product documentation. HBM production and demand estimates from TrendForce, IC Insights, and company earnings calls. DRAM pricing data from DRAMeXchange/TrendForce. Power consumption estimates derived from published MLPerf benchmarks, hardware TDP specifications, and published research on data movement energy costs. Brain metrics from neuroscience literature (Herculano-Houzel 2009, Lennie 2003, Markram et al. 2015). Neuromorphic benchmarks from Intel (Loihi 2), IBM (NorthPole), and BrainChip (Akida) published specifications and peer-reviewed papers. Market size projections synthesized from Allied Market Research, MarketsandMarkets, and IDC reports. Brain-scale power projections are the author's estimates based on published per-parameter energy metrics extrapolated to 100 trillion parameters. All charts reflect data and estimates as of April 2026.
This analysis is for educational and informational purposes only. It does not constitute financial advice. All models are simplifications of reality — projections involve significant uncertainty and should not be used as the basis for investment decisions.